
Greetings! I’m currently a PhD student at the University of Science and Technology of China. And I serve as a research intern at Tencent Youtu Lab.
My research interest includes:
- vision language models
- semantic segmentation
🔥 News
- 2026.01: 🔥 Delighted to announce that Youtu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision is released!
- 2025.12: 🔥 Delighted to announce that CrossEarth: Geospatial Vision Foundation Model for Domain Generalizable Remote Sensing Semantic Segmentation were accepted by NeurIPS 2025!
- 2025.09: 🔥 Delighted to announce that Towards Better & Faster Autoregressive Image Generation: From the Perspective of Entropy were accepted by NeurIPS 2025!
- 2025.06: 🔥 Delighted to announce that HQCLIP: Leveraging Vision-Language Models to Create High-Quality Image-Text Datasets and CLIP Models were accepted by ICCV 2025!
- 2022.10: Our DDB receives the Spotlight Award in NeurIPS 2022!

📝 Publications
(* denotes equal contribution.)
Core Author
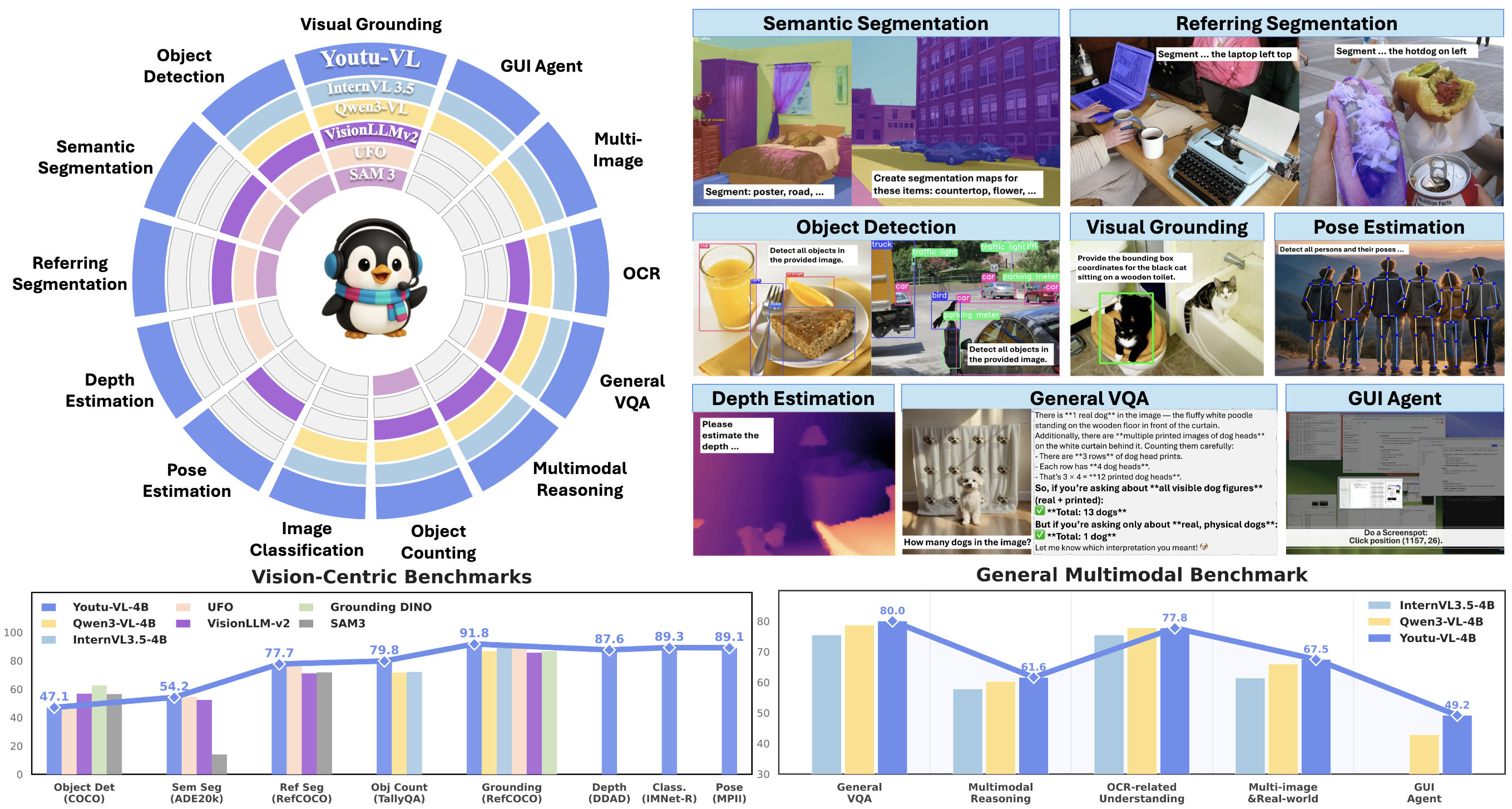
Youtu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Zhixiang Wei, Youtu-VL Team.

- Youtu-VL is a lightweight yet robust Vision-Language Model (VLM) built on the Youtu-LLM with 4B parameters. It pioneers Vision-Language Unified Autoregressive Supervision (VLUAS), which markedly strengthens visual perception and multimodal understanding. This enables a standard VLM to perform vision-centric tasks without task-specific additions. Across benchmarks, Youtu-VL stands out for its versatility, achieving competitive results on both vision-centric and general multimodal tasks.

First Author
HQCLIP: Leveraging Vision-Language Models to Create High-Quality Image-Text Datasets and CLIP Models
Zhixiang Wei*, Guangting Wang*, Xiaoxiao Ma, et al.

- We generated detailed, bidirectional long-text descriptions for 1.3 billion images and pretrained/fine-tuned CLIP based on this dataset. Building upon this foundation, we propose a novel CLIP training framework that combines both bidirectional supervision and label classification losses. This framework achieves SoTA results on zero-shot classification, retrieval, and other tasks at the same data scale.

First Author
Stronger, Fewer, & Superior: Harnessing Vision Foundation Models for Domain Generalized Semantic Segmentation
Zhixiang Wei*, Lin Chen*, Yi Jin*, Xiaoxiao Ma, et al.

- We propose the Reins framework, which efficiently fine-tunes vision foundation models for the domain generalized semantic segmentation (DGSS) task with just 1% trainable parameters, surprisingly surpassing full parameter fine-tuning. And Reins builds a new SOTA in various DGSS benchmarks.
First Author
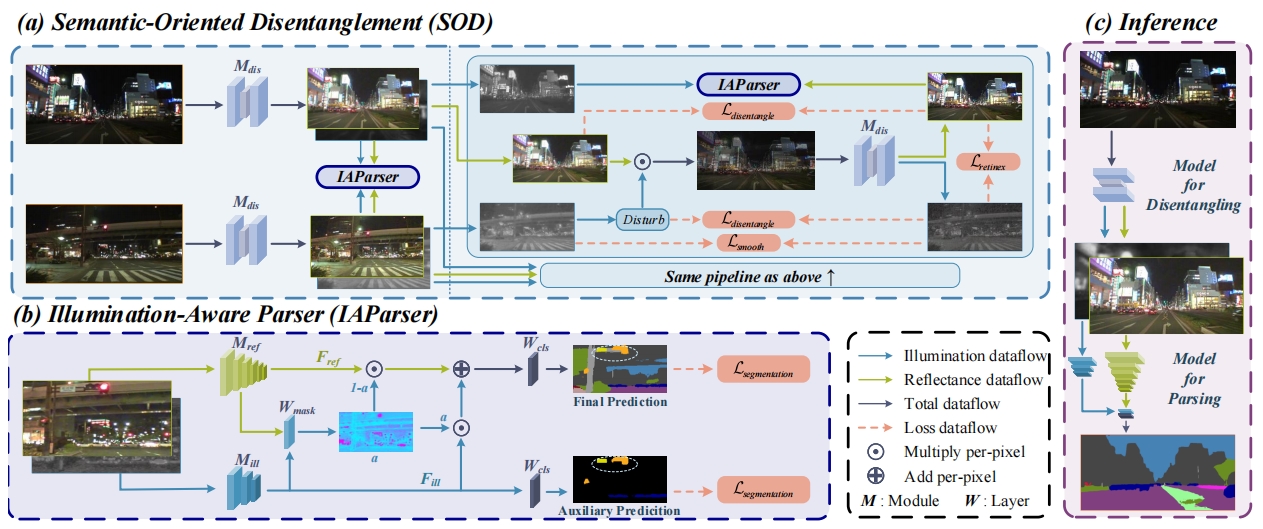
Disentangle then Parse: Night-time Semantic Segmentation with Illumination Disentanglement
Zhixiang Wei*, Lin Chen*, et al.

- We propose a novel nigh-time semantic segmentation paradigm, i.e., disentangle then parse (DTP), which explicitly disentangles night-time images into light-invariant reflectance and light-specific illumination components and then recognizes semantics based on their adaptive fusion.
Co-First Author
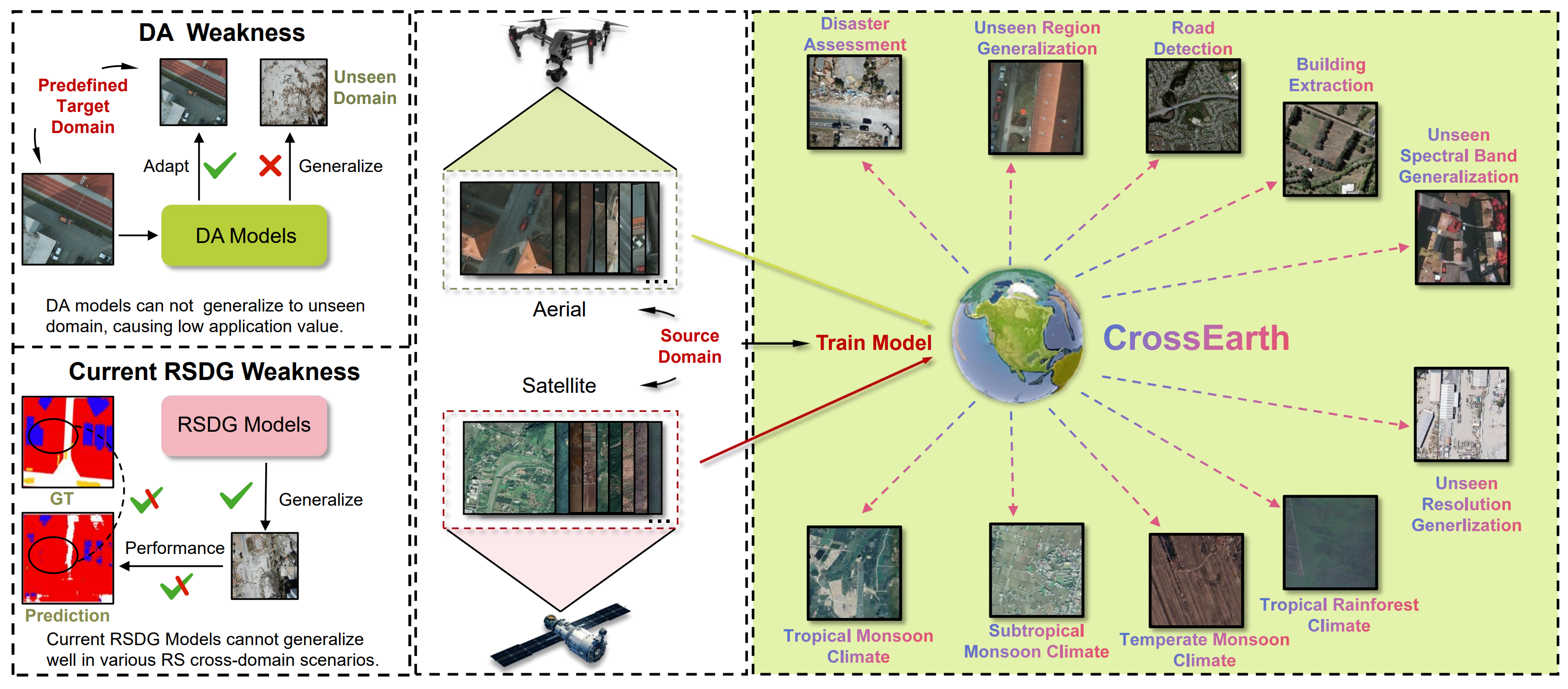
CrossEarth: Geospatial Vision Foundation Model for Domain Generalizable Remote Sensing Semantic Segmentation
Ziyang Gong*, Zhixiang Wei*, et al.

- we introduce the first vision foundation model for Remote Sensing Domain Generalizatio semantic segmentation, CrossEarth.
Co-First Author
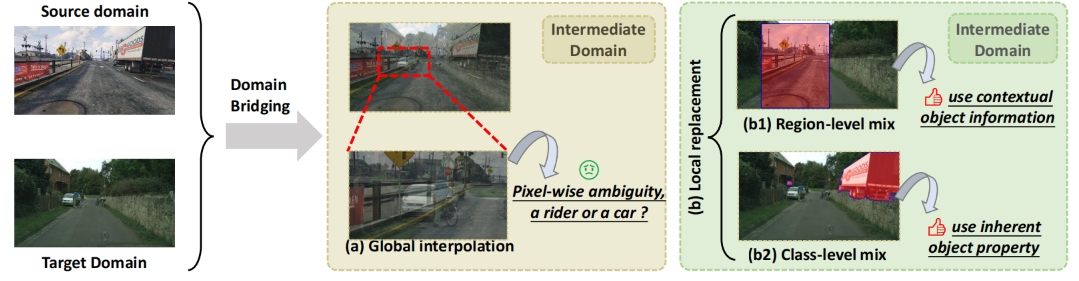
Deliberated Domain Bridging for Domain Adaptive Semantic Segmentation
Lin Chen*, Zhixiang Wei*, Xin Jin*, et al.
- We leverage the complementary characteristics of the coarse-wise and fine-wise data mixing techniques to progressively transfer the knowledge from the source to the target domain.
Co-First Author
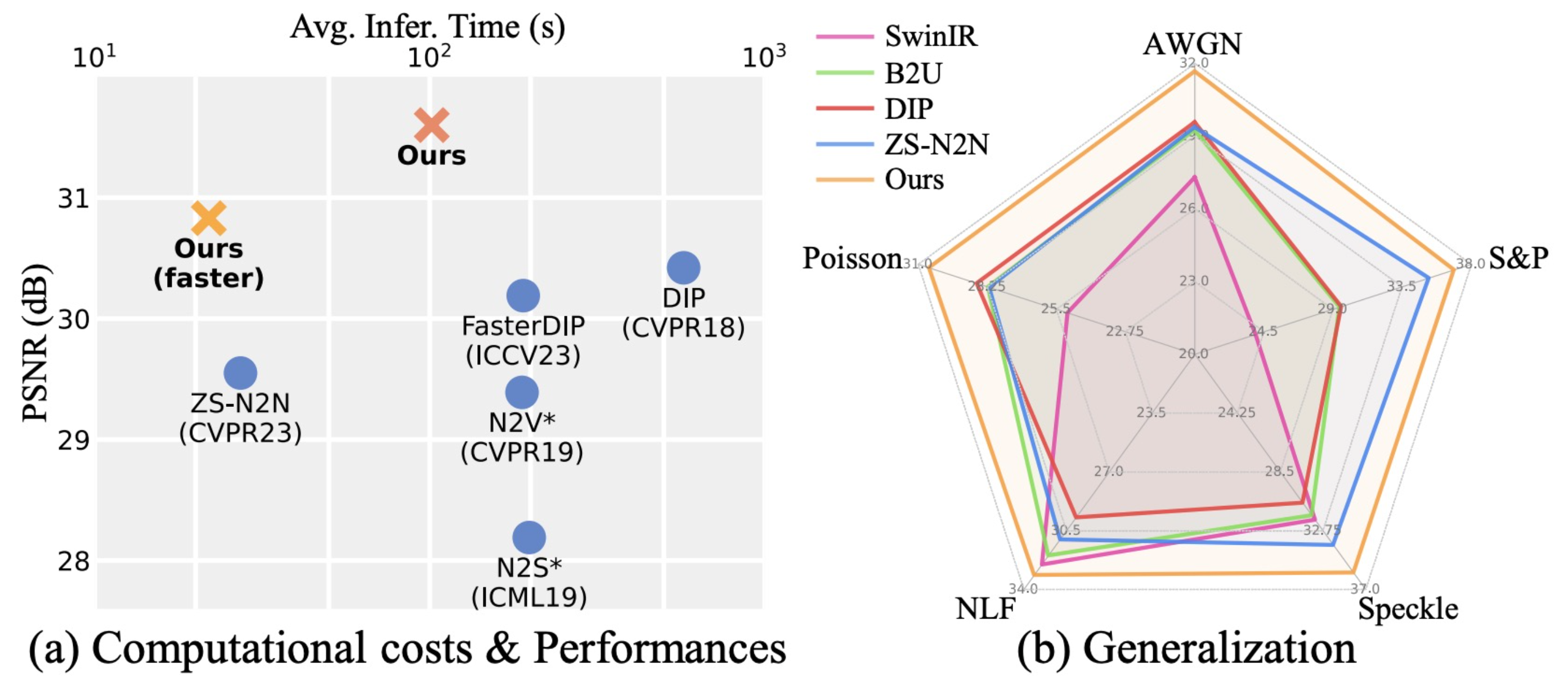
Masked Pre-trained Model Enables Universal Zero-shot Denoiser
, Xiaoxiao Ma*, Zhixiang Wei*, et al.

- MPI is a zero-shot denoising pipeline designed for many types of noise degradations.
Co-Author
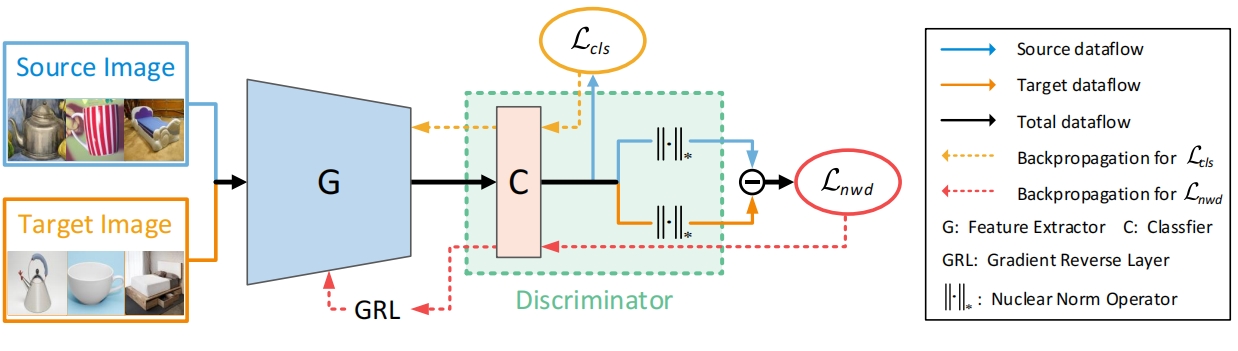
Reusing the Task-specific Classifier as a Discriminator: Discriminator-free Adversarial Domain Adaptation
Lin Chen, Zhixiang Wei, Xin Jin, Enhong Chen.

- We reuse the category classifier as a discriminator to form a discriminator-free adversarial learning framework.

Co-Author
Towards Better & Faster Autoregressive Image Generation: From the Perspective of Entropy
Xiaoxiao Ma, Zhixiang Wei, et al.

- We reuse the category classifier as a discriminator to form a discriminator-free adversarial learning framework.
🎖 Honors and Awards
- 2023.10 National Scholarship Award(Top 1%)
- 2021~2023 The First Prize Scholarship of USTC for three consecutive years
- 2021.05 Outstanding Graduates of Anhui Province
💻 Experiences
- 2025.07 - Persent, Tencent Youtu Lab.
- 2024.07 - 2025.07, WeChat Vision, Tencent Inc.
📝 Academic Service (Reviewer)
- IEEE TPAMI
- IEEE TNNLS
- IEEE TCSVT
- IEEE/CVF CVPR
- NeurIPS
💬 Invited Talks
- 2024.09 IEEE ITSC Workshop: Foundation Models for Autonomous Driving, in Canada